Если ты выбираешь STT в 2026, эта статья сэкономит тебе неделю работы. Я собрал на одном стенде и cloud-провайдеров (которые отдают только API), и open-weight-модели — которые можно скачать с HuggingFace и запустить локально без интернета. Померил на одинаковых сэмплах, чтобы цифры сравнивались честно.
Полный код, методология и интерактивные таблицы со всеми моделями — в репозитории stt-benchmarks. Здесь — выводы и почему они такие.
Что я мерил
- Сэмплы: 20 живых записей с iPhone Voice Memos — 10 RU и 10 EN. Чистая речь, быстрая разговорная, шёпот, на улице, цифры, имена собственные, code-switch RU/EN, короткие команды, длинные фразы.
- Железо: Mac mini M4 Pro, 64 GB RAM, 12 cores, без дискретной GPU.
- Метрики: WER и CER через Levenshtein, текст приводится к lowercase без пунктуации. Между cloud-запросами — 4 секунды на rate-limit. На каждую пару (модель, сэмпл) — 1 warmup и 3 измерения, в таблицу попадает медиана.
- WER clean — подвыборка без цифр и идентификаторов вроде
smolevich_voice_bot. На таких Whisper нормализует «двадцать» в «20» и ломает identifier-ы — WER артефактно вырастает до 70–95% и портит ranking.
AR vs NAR — главная развилка
Прежде чем выбирать модель, надо понять что они структурно разные. Не «одна на полпроцента точнее», а устроены изнутри по-разному.
AR — autoregressive
Кто: Whisper, ElevenLabs Scribe, Canary.
Encoder сжимает аудио, decoder генерирует текст токен за токеном — как LLM.
Плюсы: качество на 99 языках, терпит шумы, акцент, паузы.
Минусы: latency растёт с длиной выхода, нужен GPU или специализированное железо, склонна к hallucinations на тишине.
NAR — non-autoregressive
Кто: Parakeet, Moonshine, Sense Voice, GigaAM.
Encoder сжимает аудио, decoder идёт по фреймам и параллельно решает что в каждый кусочек вписать. Внутри — CTC или transducer (RNN-T, TDT).
Плюсы: latency не зависит от длины текста, стримит из коробки, CPU справляется, нет hallucinations на тишине.
Минусы: меньше языков (Parakeet TDT v3 — 25 против 99 у Whisper), хуже на странной речи.
Развилка простая:
- Расшифровать готовое аудио → AR
- Стримить речь в реалтайме на устройстве → NAR
- Batch-прогон тысяч файлов через GPU → AR
- Privacy-first на ноуте без интернета → NAR
Четыре оси выбора
Если архитектура решена, дальше — четыре фактора, которые редко выигрываются одной моделью одновременно.
- Cost. 10 000 минут в месяц: Groq Whisper Turbo ≈ $400. Parakeet local на M-чипе ≈ $30 (электричество + амортизация). Перелом около 2 000 минут/мес: до этого cloud дешевле и проще, после — local окупается.
- Latency на 10 сек аудио. Groq cloud ≈ 250 ms (network + LPU inference). Local Whisper Turbo на M-чипе ≈ 1 с. Local Parakeet TDT v3 на CPU 400–600 ms. Вывод: NAR на CPU может быть быстрее AR на GPU того же класса.
- Privacy. Медицинские записи, юридические звонки, корпоративные созвоны — cloud отпадает по compliance. Здесь local — единственный вариант, и NAR удобнее: Parakeet или GigaAM на ноуте без сети, замкнутый контур.
- Accuracy. Whisper — 99 языков, универсальный baseline. Parakeet TDT v3 — 25 языков, русский надо проверять отдельно. GigaAM v3 — RU-only, специально натренирован под русский язык. Универсальная модель не равно лучшая для конкретного языка.
Бесплатная расшифровка в боте @smolevich_voice_bot и на главной voice.smolevich.com. Под капотом — те же модели, про которые читаешь ниже.
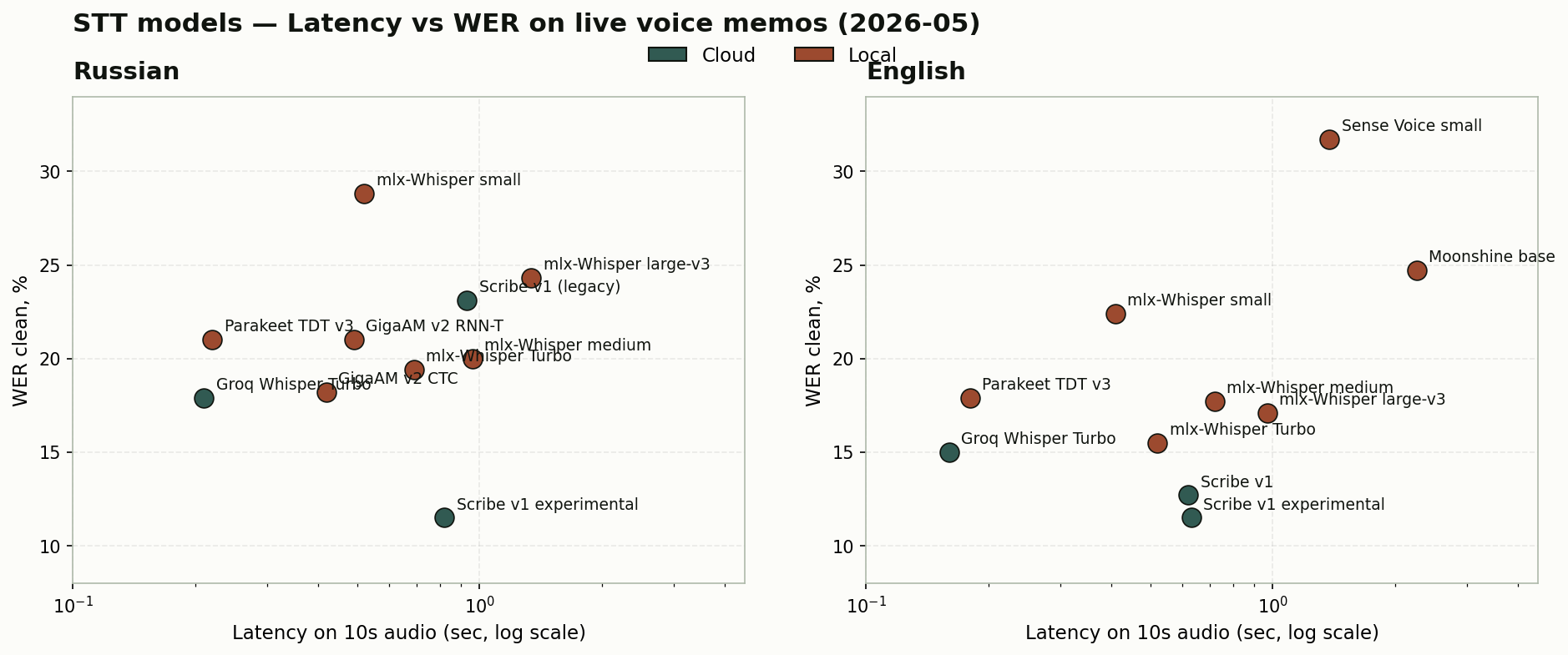
Результаты — RU, топ-5 из 11 моделей
| # | Модель | Где | Арх. | Latency / 10s | WER clean |
|---|---|---|---|---|---|
| 1 | ElevenLabs Scribe v1 experimental | cloud | AR | 0.82 с | 11.5% |
| 2 | Groq Whisper L-v3 Turbo | cloud | AR | 0.21 с | 17.9% |
| 3 | GigaAM v2 CTC | local | NAR (CTC) | 0.42 с | 18.2% |
| 4 | mlx-whisper-large-v3-turbo | local | AR | 0.69 с | 19.4% |
| 5 | mlx-whisper-medium | local | AR | 0.96 с | 20.0% |
Результаты — EN, топ-5 из 10 моделей
| # | Модель | Где | Арх. | Latency / 10s | WER clean |
|---|---|---|---|---|---|
| 1 | ElevenLabs Scribe v1 experimental | cloud | AR | 0.63 с | 11.5% |
| 2 | ElevenLabs Scribe v1 | cloud | AR | 0.62 с | 12.7% |
| 3 | Groq Whisper L-v3 Turbo | cloud | AR | 0.16 с | 15.0% |
| 4 | mlx-whisper-large-v3-turbo | local | AR | 0.52 с | 15.5% |
| 5 | mlx-whisper-large-v3 | local | AR | 0.97 с | 17.1% |
Полная таблица — все модели × оба языка, CER, latency и peak RAM — в интерактивных результатах.
Четыре главных вывода
1. Scribe experimental — лидер на обоих языках с большим отрывом.
11.5% WER на RU и 11.5% на EN — в 1.5 раза лучше следующей модели на каждом языке. И самое интересное: ровно та же Scribe v1 без _experimental на RU дала 23.1% WER — в два раза хуже. Один провайдер, один API, разница в model_id — и качество вдвое. Если не следишь за апдейтами провайдера, можешь застрять на устаревшей модели и не знать.
2. NAR обгоняет AR только если узко-специализирован под язык.
GigaAM v2 CTC (RU-only) на русском обогнал local Whisper Turbo (18.2% vs 19.4%) и почти догнал cloud Groq (17.9%). Без GPU, без сети. При этом Parakeet TDT v3 — flagship multilingual NAR на 25 языках — на обоих языках проиграл AR-универсалу Whisper-medium. Sense Voice (NAR на 50+ языках) на EN дала 31.7% WER, худший результат в наборе. Архитектура сама по себе ничего не гарантирует — побеждает узкая специализация под язык.
3. Groq Whisper Turbo — самая быстрая.
0.16 с на 10 сек аудио на EN. В 3–4 раза быстрее лучшей local-модели и в 5 раз быстрее лидера по точности. Не лидер по WER после появления Scribe experimental, но всё ещё топ-3 на обоих языках — безопасный default для real-time-сценариев.
4. Local AR на M4 Pro идёт почти вровень с cloud Groq.
mlx-whisper-large-v3-turbo даёт 19.4% RU и 15.5% EN против 17.9% / 15.0% у Groq. На EN gap 0.5 пункта, на RU — 1.5. На современном M-чипе local Whisper Turbo — практически cloud-grade.
Что используется в боте сейчас и что в планах
Сейчас @smolevich_voice_bot работает на cloud-стеке: Groq Whisper Turbo держит основной поток как быстрый default, ElevenLabs Scribe experimental доступен и на free — то есть топ-1 модель по моему бенчмарку можно попробовать бесплатно, без подписки.
Open-weight модели (GigaAM v2 CTC для RU, Parakeet TDT v3 для EN) пока в роадмапе. На M-чипах они дают почти cloud-grade WER, технически готовы — нужен продуктовый кейс, под который их включать. Если cloud для тебя отпадает (compliance, on-prem) и хочется такого режима в боте — напиши, прикручу.
В premium-тариф смотрю в сторону Fish Audio S2 — cloud-провайдер с voice cloning за 15 секунд и более мягкой экономикой чем ElevenLabs (200 минут за $5.5/мес против 30 минут за $5/мес). В этот STT-бенч не попал, протестирую отдельно когда буду подключать.
Decision matrix — что брать когда
| AR | NAR | |
|---|---|---|
| Local | Whisper Turbo (mlx) — почти cloud-grade на M-чипе | GigaAM v2 CTC (RU) / Parakeet TDT v3 (25 языков) |
| Cloud | ElevenLabs Scribe experimental — точнее всего; Groq Whisper Turbo — быстрее всего | в моём наборе не тестировал; Fish Audio S2 (cloud) — кандидат на сильную NAR-cloud-модель, в этот заход не попал |
Practical mapping:
- Продакшн voice-бот RU/EN → ElevenLabs Scribe experimental + Groq Turbo backup
- On-device EN-only app → Parakeet TDT v3 local
- Real-time live caption → Moonshine streaming local
- Дубляж EN/DE/ES/FR → Canary 1B (local или cloud)
- Batch-расшифровка тысяч файлов → mlx-whisper Turbo на M-чипе
FAQ
Какая STT-модель лучше всего работает с русским в 2026?
По прогону 20 живых RU-сэмплов — ElevenLabs Scribe v1 experimental (11.5% WER, cloud). Из local — GigaAM v2 CTC (18.2% WER, NAR, идёт на CPU). Whisper Large v3 Turbo через Groq — быстрый универсальный baseline (17.9% WER).
Whisper или Parakeet — что выбрать?
Parakeet TDT v3 покрывает 25 языков (EN + основные европейские). Если твоего там нет — Whisper, он на 99 языках. Если есть и важен on-device/streaming/offline — Parakeet. Если EN и нужна максимальная точность через API — ElevenLabs Scribe experimental.
Можно ли запустить эти модели локально бесплатно?
Да: Whisper, Parakeet, Moonshine, GigaAM, Sense Voice — все open-source, доступны через HuggingFace. Только железо и электричество. ElevenLabs Scribe и Groq Whisper — cloud-only, с поминутной оплатой.
Сколько RAM нужно?
Whisper Large — ~10 GB и желательно GPU. Whisper Turbo — ~6 GB. Parakeet TDT 0.6B — ~3 GB, идёт на CPU. GigaAM v2 — ~2 GB.
Что такое AR и NAR простыми словами?
AR (autoregressive) — модель генерирует текст токен за токеном, как GPT. NAR (non-autoregressive) — параллельно по фреймам аудио. NAR быстрее на CPU, стримит из коробки, не галлюцинирует на тишине. AR терпит больше языков и плохую запись.
Есть ли streaming в Whisper?
Нативно — нет. Только chunking-хаки: режешь аудио на 30-сек чанки, прогоняешь, склеиваешь. Streaming native — это Moonshine или Parakeet с frame-streaming оболочкой.
Расшифровать голосовое в Telegram — @smolevich_voice_bot. Попробовать в браузере, без установки — voice.smolevich.com. Под капотом — связка Groq + Scribe experimental + локальные модели для приватных сценариев.
Все данные и код открыты — stt-benchmarks.
Станислав Шупилкин — CEO и фаундер Voice AI, engineering manager, выходец из разработки. Подробнее обо мне и других проектах — на smolevich.com.