If you're picking STT in 2026, this article saves you a week of work. I put cloud-only APIs and open-weight models — the ones you can pull from HuggingFace and run on your laptop without internet — on the same bench, on the same samples, so the numbers compare honestly.
Full code, methodology and interactive tables live in the stt-benchmarks repository. Here — conclusions and why.
What I measured
- Samples: 20 live iPhone Voice Memos — 10 RU and 10 EN. Clean speech, fast conversational, whisper, outdoors, numbers, proper names, RU/EN code-switching, short commands, long sentences.
- Hardware: Mac mini M4 Pro, 64 GB RAM, 12 cores, no discrete GPU.
- Metrics: WER and CER via Levenshtein on lowercased, punctuation-stripped text. 4-second sleep between cloud requests to respect rate limits. One warmup plus three measured runs per (model, sample); medians reported.
- WER clean excludes samples heavy with digits and identifiers like
smolevich_voice_bot. Whisper normalises "twenty" to "20" and mangles identifiers — WER artificially balloons to 70–95% and skews the ranking.
AR vs NAR — the architectural fork
Before picking a model, it helps to see that they're structurally different — not "half a percent more accurate", but built differently inside.
AR — autoregressive
Who: Whisper, ElevenLabs Scribe, Canary.
Encoder compresses audio, decoder generates text token by token — like an LLM.
Pros: good on 99 languages, tolerates noise, accents, pauses.
Cons: latency grows with output length, needs a GPU or specialised inference chip for speed, prone to hallucinating on silence.
NAR — non-autoregressive
Who: Parakeet, Moonshine, Sense Voice, GigaAM.
Encoder compresses audio, decoder walks frame-by-frame and decides what to emit per slice in parallel. Internally — CTC or transducer (RNN-T, TDT).
Pros: latency independent of text length, streams natively, runs on CPU, no silence hallucinations.
Cons: fewer languages (Parakeet TDT v3 covers 25 vs Whisper's 99), worse on weird/messy speech.
Quick fork:
- Transcribe finished audio → AR is fine
- Real-time streaming, on-device → NAR
- Batch through GPUs → AR
- Privacy-first on a laptop, no internet → NAR
Four axes you actually care about
- Cost. 10 000 minutes per month: Groq Whisper Turbo ≈ $400; Parakeet local on an M-chip ≈ $30 (electricity + amortisation). Break-even around 2 000 min/mo — cloud is cheaper and simpler below that, local pays off above.
- Latency on 10s audio. Groq cloud ≈ 250 ms (network + LPU inference). Local Whisper Turbo on an M-chip ≈ 1 s. Local Parakeet TDT v3 on CPU 400–600 ms. NAR on CPU can outrun AR on a GPU of the same class.
- Privacy. Medical recordings, legal calls, internal meetings — cloud is off the table on compliance. Local is the only option, and NAR is the convenient one: Parakeet or GigaAM on a laptop with no network access.
- Accuracy. Whisper — 99 languages, universal baseline. Parakeet TDT v3 — 25 languages, RU must be verified separately. GigaAM v3 — RU-only, fine-tuned specifically for Russian. A universal model is not the same as the best model for your language.
Free transcription in the Telegram bot @smolevich_voice_bot or in your browser at voice.smolevich.com. Same models you're reading about below — under the hood.
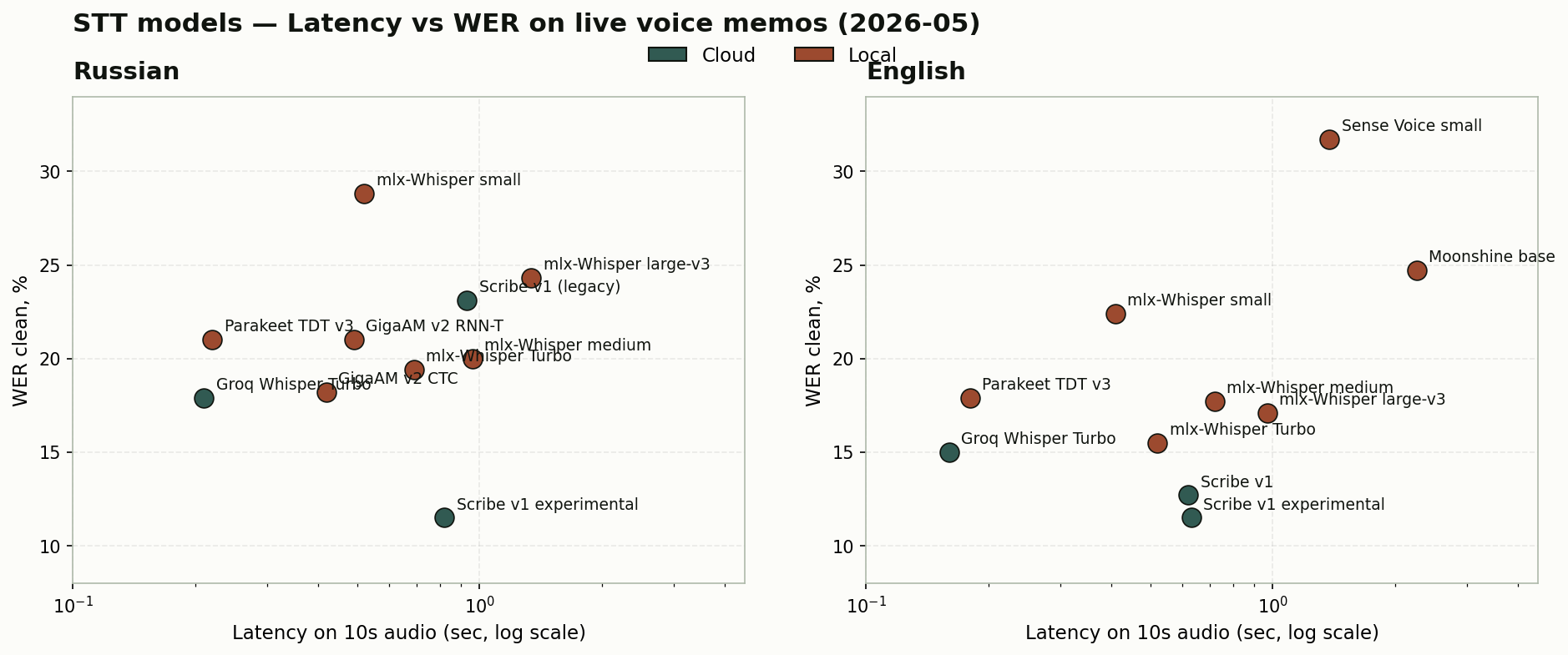
Results — RU, top-5 of 11 models
| # | Model | Where | Arch. | Latency / 10s | WER clean |
|---|---|---|---|---|---|
| 1 | ElevenLabs Scribe v1 experimental | cloud | AR | 0.82 s | 11.5% |
| 2 | Groq Whisper L-v3 Turbo | cloud | AR | 0.21 s | 17.9% |
| 3 | GigaAM v2 CTC | local | NAR (CTC) | 0.42 s | 18.2% |
| 4 | mlx-whisper-large-v3-turbo | local | AR | 0.69 s | 19.4% |
| 5 | mlx-whisper-medium | local | AR | 0.96 s | 20.0% |
Results — EN, top-5 of 10 models
| # | Model | Where | Arch. | Latency / 10s | WER clean |
|---|---|---|---|---|---|
| 1 | ElevenLabs Scribe v1 experimental | cloud | AR | 0.63 s | 11.5% |
| 2 | ElevenLabs Scribe v1 | cloud | AR | 0.62 s | 12.7% |
| 3 | Groq Whisper L-v3 Turbo | cloud | AR | 0.16 s | 15.0% |
| 4 | mlx-whisper-large-v3-turbo | local | AR | 0.52 s | 15.5% |
| 5 | mlx-whisper-large-v3 | local | AR | 0.97 s | 17.1% |
Full table — every model × both languages, with CER, latency and peak RAM — in the interactive results.
Four takeaways
1. Scribe experimental wins both languages by a wide margin.
11.5% WER on RU and 11.5% on EN — 1.5× better than the next model on each language. The interesting part: the same Scribe v1 without _experimental lands at 23.1% WER on RU, twice as bad. Same provider, same API, only the model_id differs. If you aren't watching the provider's release notes, you can get stuck on a stale model and not know.
2. NAR only beats AR when narrowly specialised on the language.
GigaAM v2 CTC (RU-only) on Russian beat local Whisper Turbo (18.2% vs 19.4%) and nearly matched cloud Groq (17.9%). No GPU, no network. Meanwhile Parakeet TDT v3 — the multilingual NAR flagship — lost to AR-generalist Whisper-medium on both languages. Sense Voice (NAR, 50+ languages) hit 31.7% WER on EN, worst in the set. Architecture alone guarantees nothing; specialisation wins.
3. Groq Whisper Turbo is the fastest.
0.16 s on 10 seconds of EN audio. 3–4× faster than the best local model and 5× faster than the most accurate one. Not the WER winner after Scribe experimental landed, but still top-3 on both languages — the safe default for real-time scenarios.
4. Local AR on M4 Pro is nearly cloud-grade.
mlx-whisper-large-v3-turbo: 19.4% RU and 15.5% EN, against 17.9% / 15.0% for Groq. EN gap is 0.5 points, RU 1.5. On a modern M-chip, local Whisper Turbo is essentially cloud-grade.
What runs in the bot now and what's on the roadmap
Today @smolevich_voice_bot runs on a cloud stack: Groq Whisper Turbo handles the default fast path, ElevenLabs Scribe experimental is available on the free tier — so the top-1 model in my bench can be tried for free, no subscription.
Open-weight models (GigaAM v2 CTC for RU, Parakeet TDT v3 for EN) are on the roadmap. On M-chips they land close to cloud-grade WER — technically ready, the gating factor is a product scenario to plug them into. If cloud is off-limits for you (compliance, on-prem) and you'd want a local mode in the bot, drop me a note.
For the premium tier I'm looking at Fish Audio S2 — a cloud provider with 15-second voice cloning and softer economics than ElevenLabs (200 minutes for $5.5/mo vs 30 minutes for $5/mo). It didn't make this STT bench; I'll test it separately when wiring it up.
Decision matrix — what to pick when
| AR | NAR | |
|---|---|---|
| Local | Whisper Turbo (mlx) — nearly cloud-grade on M-chips | GigaAM v2 CTC (RU) / Parakeet TDT v3 (25 languages) |
| Cloud | ElevenLabs Scribe experimental — most accurate; Groq Whisper Turbo — fastest | not covered in this run; Fish Audio S2 (cloud) is a likely strong NAR-cloud candidate I didn't get to in this round |
Practical mapping:
- Production RU/EN voice bot → ElevenLabs Scribe experimental + Groq Turbo as backup
- On-device EN-only app → Parakeet TDT v3 local
- Real-time live captioning → Moonshine streaming local
- EN/DE/ES/FR dubbing → Canary 1B (local or cloud)
- Batch transcription of thousands of files → mlx-whisper Turbo on M-chip
FAQ
Which STT model is best for Russian in 2026?
Across 20 live RU samples, ElevenLabs Scribe v1 experimental wins (11.5% WER, cloud). For local-only setups: GigaAM v2 CTC (18.2% WER, NAR, runs on CPU). Whisper Large v3 Turbo via Groq is the fastest universal baseline at 17.9% WER.
Whisper or Parakeet — which one should I pick?
Parakeet TDT v3 covers 25 languages (EN + the major European ones). If yours isn't there — Whisper, which spans 99. If yours is and you need on-device/streaming/offline — Parakeet. If EN and you want maximum accuracy via API — ElevenLabs Scribe experimental.
Can I run these models locally for free?
Yes: Whisper, Parakeet, Moonshine, GigaAM, Sense Voice are all open-source and available on HuggingFace. Only hardware and power cost. ElevenLabs Scribe and Groq Whisper are cloud-only, billed per minute.
How much RAM do they need?
Whisper Large — ~10 GB and ideally a GPU. Whisper Turbo — ~6 GB. Parakeet TDT 0.6B — ~3 GB, runs on CPU. GigaAM v2 — ~2 GB.
What's AR vs NAR in plain terms?
AR (autoregressive) decodes text token by token, like GPT. NAR (non-autoregressive) decides what to write in each audio frame in parallel. NAR is faster on CPU, streams out of the box, and doesn't hallucinate on silence. AR handles more languages and noisier audio.
Does Whisper support streaming?
Not natively. Only via chunking hacks: split audio into 30s chunks, run them, stitch the result. For real streaming you want Moonshine or a Parakeet frame-streaming wrapper.
Transcribe a voice message in Telegram — @smolevich_voice_bot. Or try it in the browser, no install — voice.smolevich.com. Under the hood: Groq + Scribe experimental + local models for private scenarios.
All data and code are open — see stt-benchmarks.
Stanislav Shupilkin — CEO and founder of Voice AI, engineering manager with a software-engineering background. More about me and other projects at smolevich.com.